Stop Treating Your AI Agents Like Software. Treat Them Like New Hires.
Most failed AI agent projects aren't a model problem — they're an onboarding problem. Here's the 5-step playbook for treating agents like new hires.
You bought an agent. You gave it your CRM credentials, your Stripe key, your Gmail OAuth, and access to a shared Slack channel. Three weeks later it sent fourteen duplicate follow-up emails to the same lead, refunded a customer twice, and quietly burned through $2,400 in API spend. You're staring at the bill wondering what went wrong.
Nothing went wrong with the model. Everything went wrong with your onboarding.
The operators winning with agents in 2026 stopped thinking like buyers and started thinking like hiring managers. That shift — from "deploy software" to "onboard a junior hire" — is the single biggest unlock I see when I audit broken agent stacks. Gartner now predicts over 40% of agentic AI projects will be cancelled by the end of 2027, citing escalating costs, unclear business value, and inadequate risk controls[1]. Every single one of those failure modes is a hiring problem dressed up as a technology problem.
The mental model nobody wires up
When you hire a new SDR, you don't hand them the master CRM password on day one and walk away. You give them a sandboxed account. You let them shadow for a week. You write down what "good" looks like. You define when they need to escalate. You review their first ten outbound emails before they send. You build in checkpoints.
You do none of that with the agent you just deployed. You drop it into production, give it root access, and check on it when the receipts get scary.
The reason this happens: vendors sell agents as plug-and-play. "Connect your stack in 5 minutes." That's a marketing line, not a deployment plan. The actual deployment plan is the same one your HR lead would write for a new contractor — except faster, because the agent can ramp in a week instead of a quarter.
What treating agents like new hires actually means
Five concrete shifts. Run them in this order.
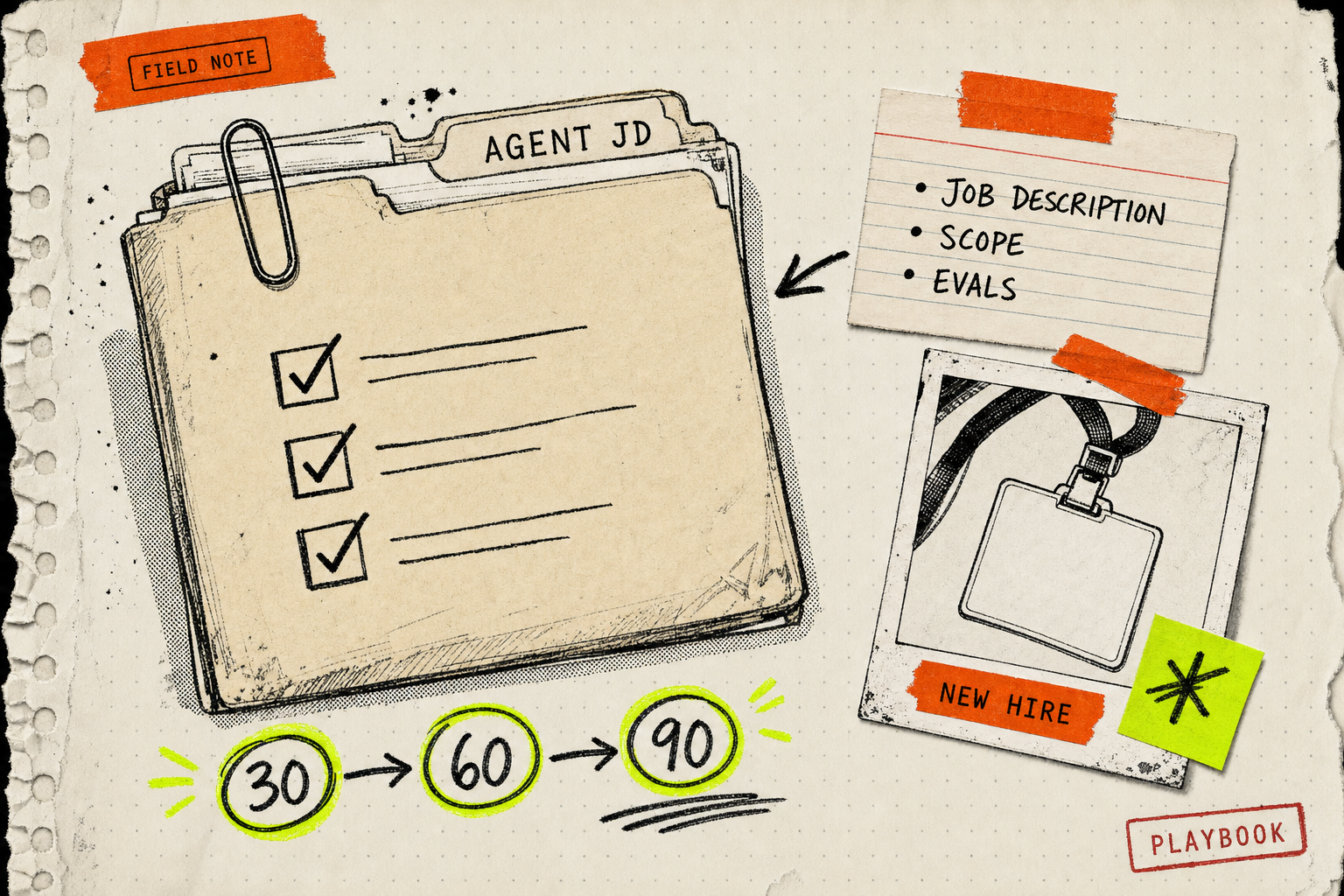
1. Write the job description first
Before you pick a model, write the agent's job description like you're going to interview a human for it. What is the one outcome it owns? What does "good" output look like? What are the three things it must never do? Which decisions does it escalate?
If you can't write that page, you don't have an agent project — you have a feature request. Most failed agent pilots I see don't have this document. The team built around what the LLM could do, not what the business needed.
2. Give it the smallest possible permission set
This is where the wheels come off most often. Operators wire the agent into everything because the demo videos do. AWS's Generative AI well-architected guidance is blunt: agentic execution roles should be developed with least-privilege access in mind, scoped to only the systems, guardrails, and data sources required for the specific task[2]. Security Boulevard puts it sharper — least privilege access for AI agents means restricting each agent's tool access, API permissions, and data scope to only what its specific task requires, nothing more[3].
A cold-outbound agent does not need refund permissions. A bookkeeping reconciliation agent does not need send-email scope. A customer-service triage agent does not need write access to your product catalog. Strip everything down. If the agent fails because it lacks a tool, you add the tool. You don't pre-grant "just in case."
OWASP's Agentic Skills Top 10 is just as direct: declare a minimal permission manifest, request only what the skill genuinely needs[4]. Different agents need different scopes, different observability, different escalation paths.
3. Run a 90-day probation with checkpoints
A new hire gets a 30/60/90. Your agent should too. Pick three checkpoints:
- Day 7 — does its output match the job description? Sample 20 actions and grade them.
- Day 30 — what's it costing per successful task? Not per token — per task. If a cold-outbound agent is costing $4 per booked meeting, that's a hire. If it's costing $4 per email sent, that's an SDR you can't afford.
- Day 90 — what would you change about the job description now that you've watched it work? Most agents that survive the cut get their scope rewritten at day 90, not at launch.
Skip these and you're not running an agent. You're running an experiment with a credit card attached.
4. Build the evals before you build the system
This is the one operators hate hearing. You need a small benchmark — 50 to 200 cases — that represents what "doing the job correctly" looks like, with expected outputs. Researchers cataloging LLM-agent hallucination types found that the most reliable mitigation is step-by-step monitoring of intermediate decisions, not end-state checks[5]. In plain English: you need to grade each step, not just the final answer.
Without evals, you have no idea if a model upgrade made the agent better or worse. You have no idea if your prompt change broke something. You're flying blind on a system that costs real money per action.
I'd rather ship an agent with a worse model and a good eval suite than the reverse. The eval suite is the thing that compounds.
5. Price the work, not the tokens
Token math will lie to you. Claude Opus 4.8 is $5 per million input tokens and $25 per million output[6] — that sounds cheap until you realize a single agent run can chain six tool calls, retry twice, and burn 80,000 tokens to do what should have been one API call.
Re-price every agent quarterly on cost-per-successful-task. Enterprises that budgeted on 2024 token rates are getting buried by 2026 agentic workflow volumes — multiples higher than their spreadsheets projected[7]. The ones who survive that bill stopped tracking spend by API line and started tracking by business outcome.
What this looks like in practice
A working agent deployment in a $5M services business this year looks like this:
- One agent owns one job (lead qualification, not "sales")
- It has access to four tools, not forty
- It has a 90-line system prompt with three explicit "do nots"
- It has an eval set of ~80 cases that gets run on every prompt change
- It runs against a sandbox CRM for the first 14 days
- It escalates anything above a confidence threshold to a Slack channel a human watches
- The bill is reviewed weekly, cost-per-task is reviewed monthly
That's not exotic. That's the same playbook a competent ops lead would use to bring a new contractor up to speed — translated into agent language.
The cost of not doing this
The 40% of agent projects Gartner says will get cancelled aren't getting cancelled because the technology failed. They're getting cancelled because the deployments were never set up to be evaluated[8]. There's no eval. There's no cost-per-task number. There's no day-7 review. So when the CFO asks "is this working," the answer is a shrug and a slide deck.
Don't be that team. The model you picked matters less than the onboarding you ran. If your agent project is wobbling, the fix is almost never "switch to GPT-5.4" — it's almost always "you skipped onboarding."
Where to start this week
Pick the one agent in your stack that's already in production. Then:
- Write its job description on one page. Today. Not tomorrow.
- Strip its permissions to the minimum the JD requires. Note what you removed.
- Build a 25-case eval. Run it. Read the failures out loud.
- Re-price it by cost-per-completed-task for the last 30 days.
You'll know within an afternoon whether you have a hire or a problem.
If you want this run for your stack — agent JDs written, scopes audited, evals built, cost-per-task scored — that's exactly the work I do on a free 30-minute audit. We'll look at one agent together and you'll leave with a one-page plan. No deck, no pitch.
-
Why over 40% of agentic AI projects will fail – and which will survive↩
Gartner predicts over 40% of agentic AI projects will be cancelled by 2027, citing rising costs, governance challenges, and lack of clear ROI.
-
GENSEC05-BP01 Implement least privilege access and permissions boundaries for agentic workflows↩
Agentic execution roles should be developed with least-privilege scoped to the specific task.
-
AI Agent Security Cheat Sheet↩
Apply least privilege to all agent tools and permissions.
-
OWASP Agentic Skills Top 10↩
Declare a minimal permission manifest; request only what the agent skill genuinely needs.
-
LLM-based Agents Suffer from Hallucinations: A Survey of Taxonomy, Methods, and Directions↩
Most reliable hallucination mitigation in LLM agents is step-by-step monitoring of intermediate decisions, not end-state checks.
-
Anthropic API Pricing in 2026: Complete Guide↩
Claude Opus 4.8 is priced at $5/$25 per million input/output tokens in 2026.
-
Perspective: AI demand is inflated, and only Anthropic is being realistic↩
Agentic usage turned what cost thousands of tokens per session into millions, breaking the economics of older budget assumptions.
-
Gartner: 40% of agentic AI projects will fail, making humans indispensable↩
Marketing leaders missing Gartner failure-mode warnings will end up in the 40% of cancelled projects.
Ready to build your own AI system?
Book a Free Audit Call →Keep Reading
Your $150K Content Team Is A Claude Skill Now
A $150K in-house content team is a 2019 answer. Here's the 4-Skill Claude stack — topic-scout, voice-draft, pre-publish-check, distribute — that ships daily for $200/mo.
The Best AI CRM For Small Business Is Not A CRM
Most 'AI CRM' pitches are dashboard candy priced like autonomous agents. Here's what a $2M-$20M business actually needs to buy, and what to skip.

You're The Bottleneck. Your AI Agents Are Waiting On You.
Your agent stack is fast. Your inbox isn't. The 3-tier autonomy fix for operators stuck approving every single agent action.