Stop Dumping Everything Into Your AI Agent. It's Why Replies Are Garbage.
Your AI agent's replies got worse because you stuffed its system prompt with everything. Context rot is real, measurable, and expensive. Here's the fix.
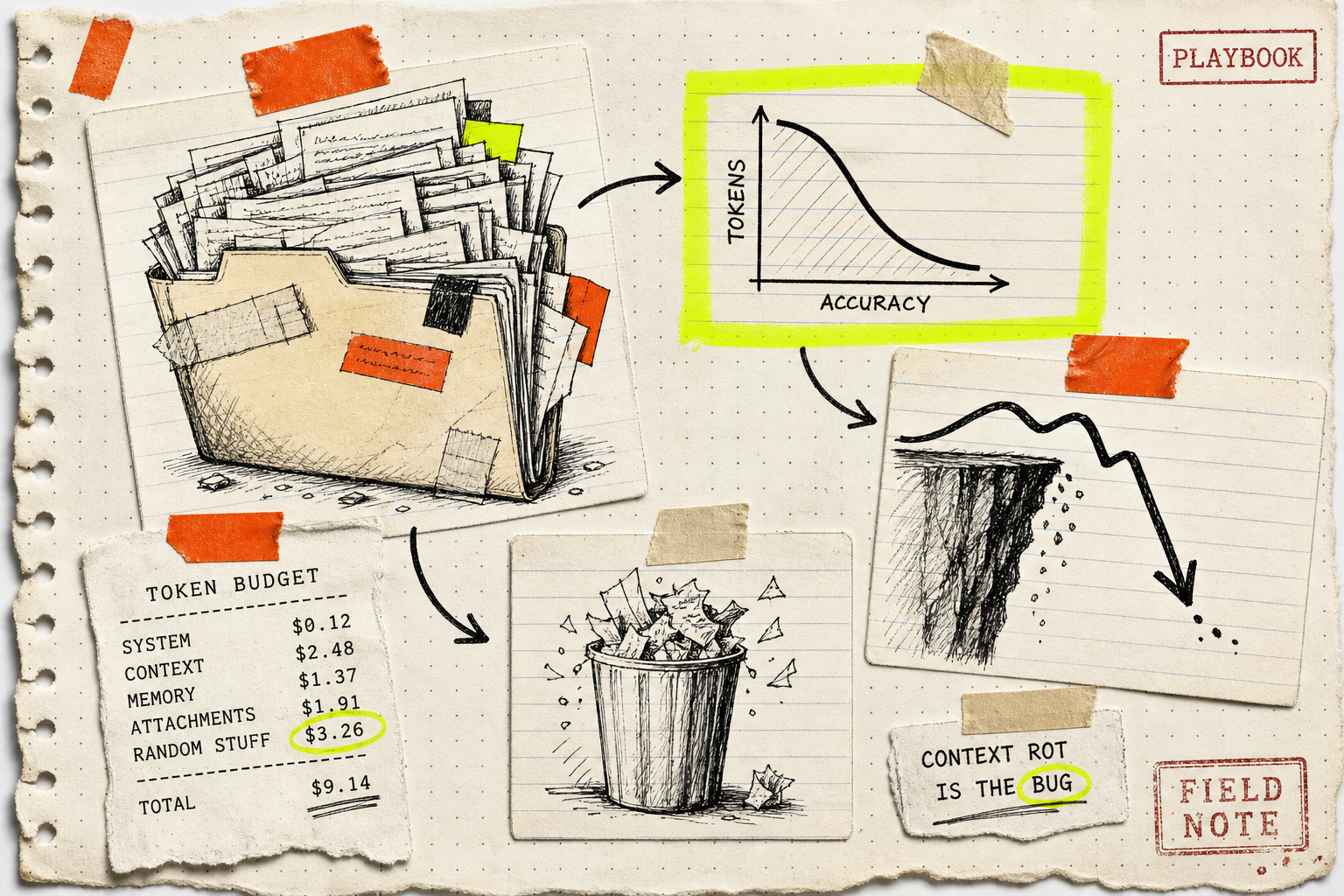
Your AI sales agent's replies got worse last month and you can't figure out why. The model didn't change. The prompt didn't change. You just added the new product catalog, the updated FAQ, last quarter's call transcripts, and a 40-page brand-voice doc to the system prompt. That's the bug. You overfed it. Now it's stupider, slower, and you're paying 3x per call to make it that way.
This is the most common failure mode I see when I audit AI agent stacks. Operators treat the context window like a hard drive — pile everything in, hope the model figures out what matters. It doesn't. The research is unambiguous on this, and the numbers are worse than most people think.
What's actually happening: context rot
Anthropic published a piece on context engineering for agents that names this directly: as you put more tokens into a model's context window, its ability to accurately recall information from that context decreases[1]. They call it context rot. Every frontier model exhibits it — Claude, GPT, Gemini. Bigger context windows didn't fix the problem. They made it easier to ignore.
The Galileo team measured the cliff. Once an agent's accumulated context crosses about 30,000 tokens, you hit "distraction limits where models start deteriorating significantly." And once a task requires more than 10 tool calls, the accumulated context starts degrading performance on its own[2]. Most production sales agents I audit are well past both thresholds before the first customer message even arrives.
The Lost-in-the-Middle paper, which is now three years old and still describes 2026 models accurately, found that accuracy drops sharply for information sitting between 10% and 50% of context depth[3]. Stuff your agent's system prompt with eight policy docs and the rules buried on page four might as well not exist. The model will hallucinate around them confidently.
NOLIMA, a more recent benchmark designed to test long-context recall without literal keyword matching, found performance degrades significantly as context length increases — at 32K tokens, 11 of the models tested fell off a cliff[4]. Your agent's 200K-token window is marketing. Its useful window is closer to 8K-16K.
Why this hits sales and support agents hardest
A sales or support agent isn't a coding agent. It doesn't get to plan, edit, retry. It gets one shot to read a customer message, fetch the right context, write a reply that sounds like you, and close the loop in under three seconds. Every irrelevant token in its prompt is a tax on that one shot.
Here's what a typical agent prompt looks like in the wild after six months of nobody pruning it:
- 2,500-word "personality" doc the founder wrote on a flight
- The full product catalog (12,000 tokens)
- 40 FAQ entries (some contradict each other)
- Three months of "good example" conversations pasted in
- A list of 27 banned phrases
- Compliance disclaimers nobody on the team can remember writing
- A reminder to always end with an emoji
That's 40K-60K tokens of system prompt before the customer says "Hi." The model now has to read all of that on every turn, which is what drives the second problem: cost.
The cost side is brutal
Long contexts aren't just dumber — they're more expensive on every dimension. They increase Time To First Token and cost real dollars per API call, which is why one engineering writeup explicitly names long-context stuffing as the failure mode RAG was invented to solve[5].
Bain's 2026 Automation & AI Pathfinder Survey, with 951 companies, found that nearly 40% of companies measuring AI cost savings landed below 10%, despite targeting 11-20%[6]. And rather than fixing the underlying architecture, 90% of those same companies are now increasing their budgets again. More money, same broken design.
One Fortune 500 quietly burned $500 million on Claude in a single month because nobody put usage limits on license-holders[7]. That's the extreme version. The version I see at the $1M-$20M tier is smaller — but the same shape. Token bills doubling quarter over quarter while reply quality drops. Nobody connects the two until I'm sitting in the audit call drawing the diagram.
The fix: context engineering, not prompt engineering
Prompt engineering is what you do once. Context engineering is what you do every turn. The question stops being "what should I tell the agent?" and becomes "what is the smallest set of tokens the agent needs to handle THIS message?"
Here's the playbook I install when I rebuild a broken agent stack.
1. Cut the system prompt to one page
The system prompt is for identity, tone, and hard rules only. Not knowledge. Not catalogs. Not FAQs. If you're over 1,500 tokens in the system prompt, you've already lost. The Anthropic guidance reinforces this — keep it lean, keep it stable, treat it like a constitution, not a textbook.
2. Move every doc to a retrieval layer
Product catalog, FAQ, brand voice doc, compliance — all of it goes into a vector store, or even a well-indexed Postgres. On each customer message, you semantically search for the top 3-5 chunks that actually match the question and inject ONLY those into context. Everything else stays out.
This is the standard RAG pattern, and it's what every serious agent stack has converged on. The Elastic team's writeup on relevance in context engineering covers the math: retrieve few, retrieve relevant, inject precise[4]. Not "stuff everything and hope."
3. Set a hard token budget per turn
I cap most production sales agents at 8,000 tokens total context per turn, including the system prompt, retrieved chunks, and conversation history. If the budget is blown, the agent summarizes older turns before adding new ones. This single rule recovers most of the reply quality I see degraded in audits.
4. Trim conversation history aggressively
Last 4-6 turns is plenty for most sales conversations. Older turns get summarized into 1-2 sentences and dropped. Most operators keep the full 40-message thread in context and wonder why the agent forgets the customer's name from message #2.
5. Test the cliff
Before you ship, run the same five customer messages at increasing context loads — 4K, 8K, 16K, 32K. Watch reply quality drop. You'll see the cliff. Then set your budget below it.
What good looks like
A well-engineered sales agent ships at around 3,000-6,000 tokens per turn, costs 60-80% less than the stuffed version, replies faster, and gets the right answer more often. It's not magic. It's architecture that respects how the model actually works versus how its marketing page describes it.
When I do a 30-minute audit on a struggling AI agent stack, the first thing I count is system-prompt tokens. About 8 out of 10 times, that one number tells me everything about why the build is underperforming.
If you want this rebuilt for your stack
If your AI agent — sales, support, internal — is getting more expensive while the replies feel worse, that's not a model problem. It's a context-engineering problem, and it's fixable in a week. Book a 30-minute audit and I'll tell you exactly where your stack is bleeding tokens and what the lean version looks like. No pitch deck.
-
Effective context engineering for AI agents↩
Defines context rot: as context grows, recall accuracy drops across all frontier models.
-
Deep Dive into Context Engineering for Agents↩
Distraction limits kick in around 30K tokens; 10+ tool calls degrade performance.
-
Lost in the Middle: How Language Models Use Long Contexts↩
Accuracy drops sharply for information at 10-50% of context depth.
-
The impact of relevance in context engineering for AI agents↩
NOLIMA benchmark: performance degrades significantly as context length increases.
-
Long Context LLMs and the Lost in the Middle Phenomenon Explained↩
Long-context stuffing increases TTFT and cost, which RAG was designed to solve.
-
Your AI Budget Is Growing. Your Returns Aren't. Here's Why.↩
40% of companies measuring AI savings landed below 10%; 90% are increasing budgets anyway.
-
Unfortunate Company Accidentally Blows Half a Billion Dollars on Claude in One Month↩
Unnamed company spent $500M on Claude in one month due to no usage caps.
Ready to build your own AI system?
Book a Free Audit Call →Keep Reading
Stop Treating Your AI Agents Like Software. Treat Them Like New Hires.
Most failed AI agent projects aren't a model problem — they're an onboarding problem. Here's the 5-step playbook for treating agents like new hires.
Your AI Customer Service Bot Is About To Cost You A Lawsuit
Air Canada lost. Klarna reversed. DPD's bot wrote a poem about how terrible the company was. Here's how to deploy AI customer service without becoming the next headline.

Your AI Agent Bill Is Out of Control. Here's the Fix.
AI agents burn 50x more tokens than chats. The fix isn't a cheaper model — it's a tighter system. Token budgets, model routing, context pruning, deterministic off-ramps.