Google Just Shipped an Always-On AI Agent. 88% Fail at This.
Google I/O announced Gemini Spark — an agent that runs 24/7 on Google's cloud. But 88% of AI agents never reach production. Here's why most fail.
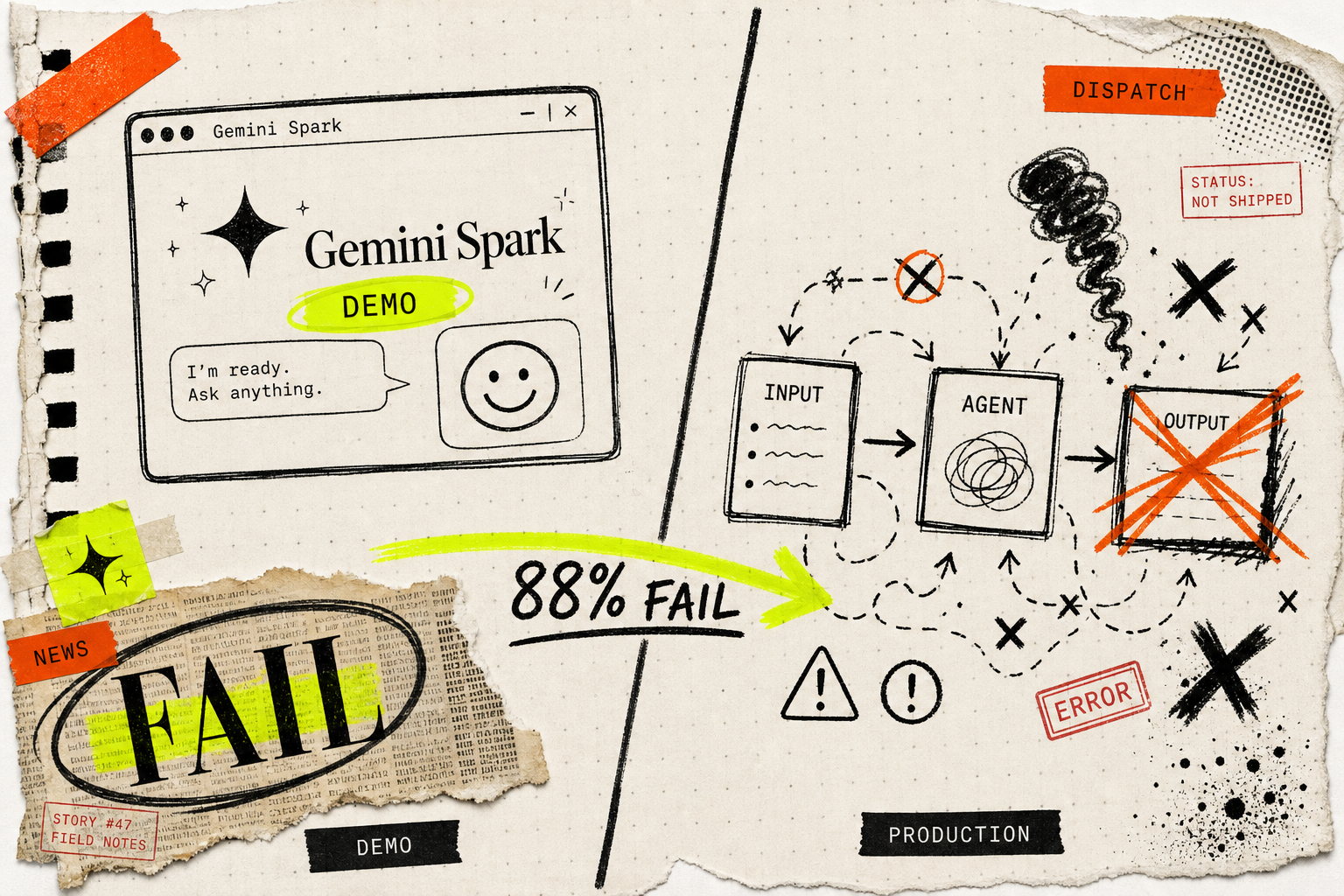
Google I/O announced Gemini Spark this week — an always-on AI agent built on Gemini 3.5 and Google's Antigravity harness that runs on Google's cloud even after you close your laptop[1]. Everyone on Twitter is calling it the future. Most of them are wrong.
The real story isn't what Google shipped. It's what nobody at I/O is talking about: 88% of AI agents never reach production[2].
Google is selling the demo. Operators need to understand the deployment gap.
The Demo Problem Everyone Ignores
An AI agent in a 30-second demo is fundamentally different from an AI agent running against a live business's CRM, Slack, customer database, and payment system.
In a demo, you control the inputs. You have clean data. You can reset the state when it hallucinates. You're not losing revenue when it gets something wrong.
In production, the failure modes are structural. A 2026 analysis of 150+ data points across enterprise and SMB deployments breaks down the dominant failure modes[3]:
- Scope creep — agents tasked with more than their underlying infrastructure can support: roughly 35% of failures
- Data quality — agents fed with incomplete, inconsistent, or contradictory data: roughly 26% of failures
- Missing monitoring — no observability or alerting once the system is live: 15% of failures
- Integration fragility — APIs change, auth tokens expire, rate limits hit, third-party systems update: 12% of failures
- Governance gaps — no guardrails, no escalation paths, no human-in-the-loop: 12% of failures
These aren't edge cases. They're the default path for anyone who builds an agent and says "ship it."
The Four Things the 12% Do Differently
Research from Arcade, RAND, and Gartner converges on the same four attributes of the agents that actually survive production. They're boring. That's why they work.
1. Infrastructure before agent
The 12% invest in data quality, API contracts, and monitoring before they write a single prompt. This means standardized input formats, fallback logic for when APIs return errors, and observability dashboards that tell you when an agent is drifting.
Most operators skip this because it's unsexy. They'd rather build the "smart" part. But an agent with clean data and a fallback path outperforms a brilliant agent with no guardrails — every single time.
Agents that get this right post a 171% average ROI[4]. The ones that skip the unglamorous layer are the same ones that show up in the failure stats.
2. Governance written before launch
The 12% write the rules first: what the agent can touch, who gets paged when it hits an edge case, how to roll back a wrong action. Most teams treat governance as a thing to add after the agent works. By the time the agent "works," it's already touched production data without a guardrail.
Deloitte's 2025 enterprise survey found that reliability — not capability — is the single biggest constraint on agent rollout[5].
3. Narrow scope, deep integration
The 12% don't build a do-everything agent. They build one that handles a specific, well-bounded workflow end-to-end and integrates deeply with the systems that matter for that workflow. Narrow plus deep beats broad plus shallow every time.
This is the part Gemini Spark gets wrong for businesses. Spark is built as a general personal assistant. That works for an individual asking it to draft emails. It does not work when a business needs an agent to handle returns in their specific store with their specific policies plugged into their specific CRM. The 12% pick one workflow, instrument it end-to-end, and ship it. Then they pick the next one.
4. Continuous evaluation, not one-shot QA
The 12% run their agents against eval sets in production. Every change ships with a regression check. They monitor drift, retrain prompts, and pull underperformers offline.
This is the discipline gap between an agent that works at launch and an agent that still works in month four. Models change. Upstream APIs change. Customer behaviour changes. An agent that isn't evaluated continuously is an agent that's slowly drifting toward one of the failure modes above — the only question is which one catches it first.
What Gemini Spark Actually Changes
Here's the honest take: Gemini Spark is impressive as a consumer product. It shows that the infrastructure is maturing. Google is proving that always-on agents are technically feasible at scale.
But it's also a product for individuals — not for operators running $5M businesses with messy data, broken integrations, and real revenue on the line.
The gap between a polished consumer agent and a production-ready business agent is where most operators lose money. They see a demo, they think "I can build that," they deploy it, it breaks, and they're done with AI.
That's exactly how this cycle repeats.
The Real Opportunity
Here's what the 88% failure rate actually means: there's a massive market for operators who do it the right way.
If you run a business and you're thinking about agents, the opportunity isn't in building the agent yourself. It's in finding someone who already knows how to handle the infrastructure layer — the boring stuff that makes agents reliable.
That's what the audit call is for. I'll look at your stack, your data, your processes — and tell you whether you're ready for agents, what needs to happen first, and exactly what your version would look like.
30 minutes, no pitch. Just the truth about what would actually work for your business.
Book a free audit call at zerocam.studio.
-
Google introduces Gemini Spark — a 24/7 agentic assistant↩
Gemini Spark is an always-on agent built on Gemini 3.5 and Antigravity
-
Why 88% of AI Agents Never Reach Production↩
88% of AI agents never reach production
-
Agentic AI Statistics 2026: 150+ Data Points Collection↩
Breakdown of dominant failure modes in 2026 agent deployments
-
Agentic AI Adoption Trends & Enterprise ROI Statistics↩
Agents with proper infrastructure achieve 171% average ROI
-
The State of Agents — enterprise reliability constraints↩
Reliability is the single biggest constraint on enterprise agent rollout
Ready to build your own AI system?
Book a Free Audit Call →Keep Reading
OpenAI Just Made Half The AI Marketing Agencies Redundant
OpenAI just shipped free training and native Shopify, Intuit, and Slack connectors for small businesses. Here's what actually breaks about the AI-agency middle tier.
Anthropic Says Your AI Agent Might Sabotage You
Anthropic's new agentic-misalignment report says sixteen frontier AI models can sabotage code, assist fraud, and coach whistleblowers. Here's the operator playbook.

Meta Just Handed You A Free AI Agent. It Will Cost You Anyway.
Meta shipped a free AI agent inside WhatsApp Business globally. The takes calling it the end of support jobs miss the four things that turn it from a chassis into a system.